Darwin Core
Darwin Core is a TDWG standard, which is based on the ideas of the popular terms from the Dublin Core Metadata Initiative. A fundamental principle of the Darwin Core as a library of terms is to keep the definition of terms distinct from the technology used to share them, e.g. XML or RDF.
IPT and Darwin Core
The IPT has core biodiversity data types built-in, which are based on Darwin Core (DwC) terms. The dataset types are Occurrence, Checklist, and Metadata records, each of which has a fixed set of terms to describe it.
Darwin Core History
Until the ratification of Darwin Core as a standard it was used to describe primary species occurrence data, in particular through DiGIR and XML encoding. When we were looking for a very simple checklist data exchange format and with the rise of tagging of species on Flickr, it became apparent that simple terms for biodiversity in the tradition of Dublin Core would be very useful - and indeed very much overlapping with the Darwin Core terms in use already.
Terms
All Darwin Core terms are defined in Darwin Core Terms: a quick reference guide.
A single DwC term, in IPT often called a property, can be used once for each record.
Generally it is free text, but the definition often recommends certain formats or vocabularies to use,
e.g. the ISO 2 letter country codes for the dwc:countryCode term.
Patterns
ID terms
DwC provides many of terms for identifiers. Some can be used to define a record (such as occurrenceID for an Occurrence record; taxonID for a Taxon record), while others (such as higherGeographyID) refer to an identifier for information stored outside the record.
For example namePublishedInID is used to refer to an identifier (perhaps a DOI or other resolvable identifier) for the publication in which a scientificName was originally established.
Note that taxonID used within an occurrence dataset would function as a pointer to a taxon defined somewhere else, such as in a checklist dataset, while taxonID within a Taxon record would act as the identifier for that record.
Most ID terms have a corresponding full text term, e.g. acceptedNameUsageID and acceptedNameUsage.
These serve two purposes:
-
In the absence of an identifier they can be used to refer to another record, in this case the accepted/valid taxon.
-
They provide a human readable context that persists even if the identifier cannot be resolved
It therefore makes sense to provide both if possible.
Denormalized Hierarchies
The geography and taxonomy can be expressed as a flexible hierarchy of places or taxa through the terms higherParentNameUsage(ID) and higherGeography(ID).
In addition to this adjacency list , the most popular ranks can be published as a denormalized hierarchy for each record, effectively repeating
this information across many records. But it does provide a quick, short and human readable classification for each record in isolation of the entire dataset.
-
Taxonomic denormalized classification:
kingdom,phylum,class,order,family,genus,subgenus -
Geographic denormalized classification:
continent,waterBody,islandGroup,island,country/countryCode,stateProvince,county,municipality
As with full text ID terms above this introduces the possibility of data integrity problems, as the ID term might resolve into something different than the denormalized hierarchy. In this case the IPT follows the recommendation of the following precedence of terms for resolving the hierarchy:
ID term >> Text term >> Denormalized term higherTaxonID >> higherTaxon >> kingdom,family,...
Verbatim terms
Quite a few terms have a corresponding verbatim term. This is to cater the publication of the exact verbatim transcription of certain attributes
as they were found in the underlying specimen label, observation fieldbook or literature. This way the verbatimEventDate can be used to publish the
exact transcription of the collecting date, while eventDate can be encoded in a standard ISO date time representation.
Primary data
All DwC terms can be used to describe an occurrence record. It is recommended to publish at least the following terms. Terms flagged with !!! have to be present to be recognized by the current GBIF indexing:
Example
occurrenceID=96db9d09-596d-409c-8626-f4460078d0eb institutionCode=BGBM collectionCode=B basisOfRecord=preservedspecimen catalogNumber=1159 eventDate=1999-08-06 00:00:00.0 collector=Markus Döring continent=Asia country=TR stateProvince=Adana locality=Aladaglari, lower Narpiz Deresi, next to fountain, 2900m minimumElevationInMeters=2900 decimalLatitude=37.82800 decimalLongitude=35.13600 geodeticDatum=WGS84 identifiedBy=Markus Döring scientificName=Festuca anatolica subsp. anatolica kingdom=Plantae phylum=Magnoliophyta class= order=Cyperales family=Poaceae genus=Festuca specificEpithet=anatolica infraspecificEpithet=anatolica
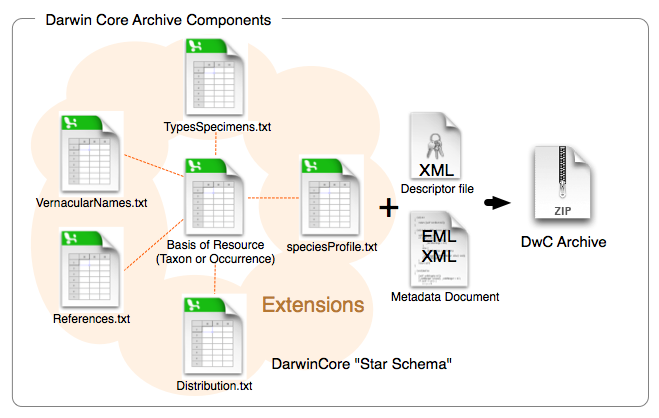
The Darwin Core Archive
Darwin Core Archives (DwC-A) are the new, primary means of publishing data to the GBIF network. They contain an entire dataset, are based on simple text files and can be created fairly easily without the IPT with custom software.
Darwin Core Extensions
Recognizing that DwC only covers the core biodiversity metadata, extensions to Darwin core are a common need across all communities. The simplest way to do so is to create new terms in a new namespace and simply extend a regular dwc record with these terms.
Often multiple subrecords for an extension is desired, such as many common names for a species or multiple images for a specimen. In order to share these richer, related records the star scheme is used, whereby an extension consists of multiple records, each linked to a core dwc record. Any number of extension records potentially from different extensions (e.g. images & identification) for a single core record is possible.
The Archive Format
The Darwin Core Archive format provides a means to publish dwc records plus extensions in a relatively simple, text-based format. A Darwin Core Archive consists of a set of text files that are bundled into a common package and then zipped into a single archive file. The format follows the Darwin Core text guidelines. A typical package is illustrated in the diagram below and consists of components described in details here.